Thorsten Alteholz: My Debian Activities in November 2020
FTP master
Unfortunately a day only has 24h. As the freeze is approaching, I had to concentrate a bit more on keeping my packages in shape. So this month I only accepted nine packages. The good news, I rejected no package. The overall number of packages that got accepted was 328.
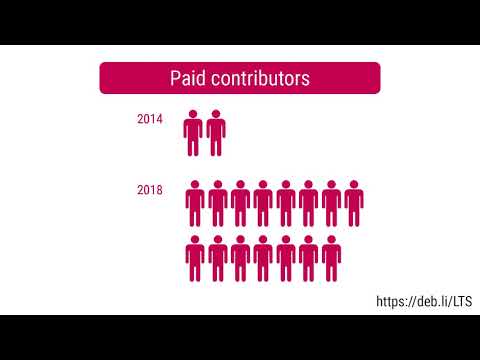
Debian LTS
This was my seventy-seventh month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
This month my all in all workload has been 22.75h. During that time I did LTS uploads of:
- [DLA 2446-1] moin security update for two CVEs
- [DLA 2451-1] libvncserver security update for one CVE
- [DLA 2459-1] golang-1.7 security update for two CVEs
- [DLA 2460-1] golang-1.8 security update for three CVEs
- [DLA 2468-1] tcpflow security update for one CVE
- [DLA 2469-1] qemu security update for five CVEs
- ELA-319-1 for libass
- ELA-320-1 for tcpflow
- ELA-321-1 for qemu
- golang-github-apparentlymart-go-cidr
- golang-github-apparentlymart-go-versions
- golang-github-bmatcuk-doublestar
- golang-github-cactus-go-statsd-client
- golang-github-cyberdelia-heroku-go
- golang-github-gin-contrib-cors
- golang-github-gin-contrib-gzip
- golang-github-jarcoal-httpmock
- golang-github-mattetti-filebuffer
- golang-github-nrdcg-goinwx
- golang-github-phpdave11-gofpdi
- golang-github-terra-farm-udnssdk
- meep
- golang-github-rs-zerolog
- bottlerocket
- ent
- golang-github-abdullin-seq
- golang-github-bruth-assert
- golang-github-cnf-structhash
- golang-github-crossdock-crossdock-go
- golang-github-dchest-uniuri
- golang-github-deanthompson-ginpprof
- golang-github-dreamitgetit-statuscake
- golang-github-facebookgo-inject
- golang-github-facebookgo-structtag
- golang-github-gin-contrib-static
- golang-github-goji-httpauth
- golang-github-grafana-grafana-plugin-model
- golang-github-hansrodtang-randomcolor
- golang-github-hashicorp-terraform-svchost
- golang-github-icrowley-fake
- golang-github-jackc-fake
- golang-github-joyent-gocommon
- golang-github-joyent-gosdc
- golang-github-joyent-gosign
- golang-github-mitchellh-go-linereader
- golang-github-paypal-gatt
- golang-github-pearkes-cloudflare
- golang-github-pearkes-dnsimple
- golang-github-robfig-go-cache
- golang-github-sean pager
- golang-github-sean seed
- golang-github-shurcool-gopherjslib
- golang-github-vividcortex-mysqlerr
- golang-github-xlab-handysort
- golang-github-yudai-golcs
- golang-github-yvasiyarov-newrelic-platform-go
- golang-github-zenazn-goji
- golang-github-rs-xid
 Welcome to gambaru.de. Here is my monthly report (+ the first week in November) that covers what I have been doing for Debian. If you re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games
Welcome to gambaru.de. Here is my monthly report (+ the first week in November) that covers what I have been doing for Debian. If you re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games




 Here is another monthly update covering what I have been doing in the free software world during August 2020 (
Here is another monthly update covering what I have been doing in the free software world during August 2020 (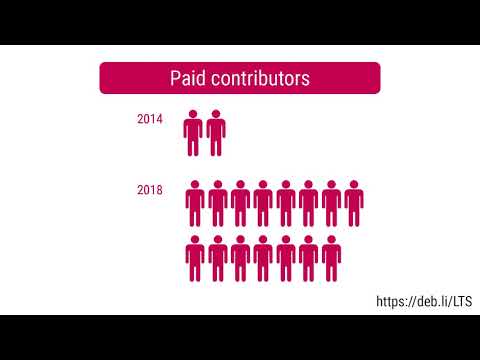
 More than a month has passed since the last update of TeX Live packages in Debian, so here is a new checkout!
More than a month has passed since the last update of TeX Live packages in Debian, so here is a new checkout! All arch all packages have been updated to the tlnet state as of 2020-06-29, see the detailed update list below.
Enjoy.
New packages
All arch all packages have been updated to the tlnet state as of 2020-06-29, see the detailed update list below.
Enjoy.
New packages
 TLDR:
TLDR:  Here is my monthly update covering what I have been doing in the free software world during February 2020 (
Here is my monthly update covering what I have been doing in the free software world during February 2020 (




 I started web development around late 1994. Some of my earliest paid web work is
I started web development around late 1994. Some of my earliest paid web work is  If you read
If you read 